الگوریتمهای یادگیری تقویتی (RL) در مقایسه با یادگیری عمیق که در دهه گذشته بسیار قویتر شده است، بسیار دشوار هستند و به انتخاب هایپرپارامترهای سخت حساس هستند. آیا RL به همین ترتیب پیشرفت خواهد کرد؟ آنها نسبت به انتخاب هایپرپارامتر بسیار حساس هستند و مدلی که در تنظیم هایپرپارامترها دقیق عمل کرده باشد، ممکن است 10 تا 100 برابر عملکرد بهتری داشته باشد.
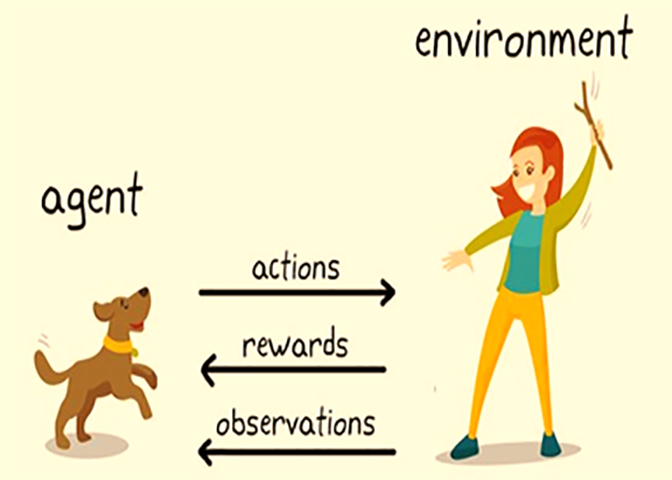
آیا الگوریتمهای یادگیری تقویتی (RL) نیز در دهه آینده قویتر خواهند شد؟ احتماش هست ولی با این حال، RL با یک مانع منحصر به فرد در دشواری ایجاد معیارهای دنیای واقعی (غیر شبیه سازی) مواجه است. زمانی که یادگیری عمیق تحت نظارت در مراحل اولیه توسعه بود، تیونرهای هایپرپارامتری با تجربه می توانستند نتایج بسیار بهتری نسبت به تیونرهای کم تجربه دریافت کنند. ما باید معماری شبکه عصبی، روش منظمسازی، نرخ یادگیری، زمانبندی کاهش نرخ یادگیری، اندازه کوچک دستهای، مومنتوم، روش اولیهسازی و غیره را با دقت انتخاب کنیم. انتخاب دقیق این پارامترها تفاوت زیادی در سرعت همگرایی و عملکرد نهایی الگوریتم ایجاد می کند. به لطف پیشرفت تحقیقات در دهه گذشته، ما اکنون الگوریتمهای بهینهسازی قویتری مانند Adam، معماری شبکههای عصبی بهتر، و راهنماییهای سیستماتیکتر برای انتخاب پیشفرض بسیاری از هایپرپارامترهای دیگر داریم که دستیابی به نتایج خوب را آسانتر میکند. اگر یک شبکه 1000 پارامتری را روی 100 مثال آموزش میدهید، انتخاب دقیق هر پارامتر اهمیت به مراتب بیشتری نسبت به شبکه ای با پارامترهای کمتر و مثالهای بیشتر دارد. محققان RL را برای اتومبیل ها، هلیکوپترها، چهارپاها، مارهای روباتی و بسیاری از برنامه های کاربردی دیگر اعمال کرده اند. با این حال بکارگیری الگوریتمهای RL امروزی هنوز هم مشکل هستند. در حالی که تنظیم ضعیف هایپرپارامترها در یادگیری عمیق ممکن است به این معنی باشد که الگوریتم شما 3 برابر یا 10 برابر کندتر آموزش ببنید، لکن در یادگیری تقویتی، به نظر می رسد که ممکن است 100 برابر کندتر عمل کند، اگر اصلاً همگرا شود! مشابه یادگیری تحت نظارت یک دهه پیش، تکنیکهای متعددی برای کمک به همگرایی الگوریتمهای RL (مانند یادگیری Q double، ...( ایجاد شده است. همه آنها باهوش هستند ، اما بسیاری از این تکنیکها هایپرپارامترهای اضافی ایجاد میکنند که به نظر می رسد تنظیم آنها بسیار دشوار است. تحقیقات بیشتر در RL ممکن است مسیر یادگیری عمیق تحت نظارت را دنبال کند و الگوریتمهای قویتر و راهنماییهای سیستماتیک را برای نحوه انجام این انتخابها به ما بدهد. در یادگیری نظارت شده، مجموعه دادههای صحیح، جامعه جهانی محققان را قادر میسازد تا الگوریتمها را بر اساس مجموعه دادههای مشابه تنظیم کنند و مدل خود را بر روی مدل دیگران بنا کنند. در RL، معیارهایی که بیشتر مورد استفاده قرار می گیرند، محیط های شبیه سازی شده مانند OpenAI Gym هستند. اما دریافت الگوریتم RL برای کار بر روی یک ربات شبیه سازی شده بسیار ساده تر از کارکرد آن بر روی یک ربات فیزیکی است. بسیاری از الگوریتم هایی که در شبیه سازی به خوبی کار می کنند با روبات های فیزیکی چندان عملکرد مناسبی ندارند. حتی دو نسخه از طراحی یک ربات متفاوت می تواند باشد. در حالی که محققان در حال پیشرفت سریع در RL برای ربات های شبیه سازی شده (و برای بازی های ویدیویی) هستند، پل ارتباطی برای کاربرد در محیط های غیر شبیه سازی شده اغلب وجود ندارد. بسیاری از آزمایشگاههای تحقیقاتی عالی روی روباتهای فیزیکی کار میکنند. اما از آنجایی که هر ربات منحصربهفرد است، تکرار نتایج یک آزمایشگاه برای آزمایشگاههای دیگر دشوار است و این مانع از سرعت پیشرفت میشود.
گردآورنده: صانع کریمی